FAQ on the PKP-Dataverse integration Project
What is the Dataverse Network?
The Dataverse Network is an open source web application for publishing, citing, analyzing and preserving research data. Supports the sharing of open data, which enables reusable and reproducible research. Researchers, data authors, publishers, data distributors, and affiliated institutions all receive appropriate credit.
What is PKP’s integration with the Dataverse Network?
This integration allows journals to facilitate research data sharing and archiving by setting up a plugin in their Open Journal Systems (OJS) (journal management & publication platform) installation for authors to be able to deposit their research data via a Data Deposit API (SWORDv2-compliant) at the same time as their article from the journal's article submission system (Note: This plugin will eventually be available for OMP and OCS.) This plugin can be used alongside OJS' current "supplementary files" option, but will also provide access to Dataverse features: data preservation, citation and analysis tools at the journal/article level. OJS Journal integration with the Dataverse Network is available for any OJS journal that wishes to implement easy data sharing and archiving, and enhance their published articles with links to data.

What are the advantages to this integration?
Advantages include:
- enabling journal editors/reviewers the ability to seamlessly manage the submission, review, and publication of data associated with published articles;
- streamlining the authors’ article and corresponding data deposit process;
- permanently linking the published article with its archived data and enhancing their visibility;
- allowing authors to deposit varied data types in robust reusable preservation-friendly formats;
- ensuring that data files are discoverable, indexed, and exposed to both web and bibliographic search engines;
- enabling research data replication and reuse essential to scholarly work;
- increasing the transparency and accountability of research;
- and permitting embargoes to delay release of data, in accordance with journal policy.
How does it work?
To make data sharing and archiving as easy as possible for authors, data files are deposited in conjunction with the journal’s article submission process, resulting in a permanent 2-way linking between an article and its corresponding data:
The Author submits their article and research data to the journal's OJS article submission system. [Note: The article and data do not have to be submitted at the same time. Authors can also submit data at a later time, or just provide a persistent link with a data citation pointing to the repository that their data is currently in.]
Editors and/or Peer Reviewers review the article and data.
If the article and corresponding research data are approved for publication the Authors' research data and it’s corresponding metadata is automatically deposited from OJS into the Dataverse Network through an API (SWORDv2-based). No redundant information need be entered. A permanent identifier (DOI) will be automatically included that allows the data to be cited and tracked. There will be a data citation included in the journal article page in OJS (and ideally within the Reference section of the article) enabling readers of the article to quickly access the data.
- The Dataverse Network stores the dataset metadata, files (including raw data, documentation, code, etc). There will also be a permanent publication citation link within the Dataverse Network for researchers to access the article in OJS that corresponds to this research data.
Data Publishing Workflow A
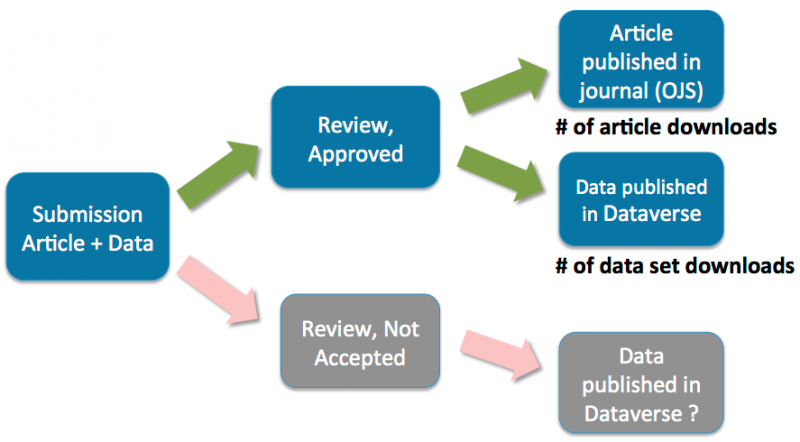
Data Publishing Workflow B

Who do I contact if I have any questions or am interested in participating in the project?
Institutions, editors and/or publishers interested in implementing this integration may review our documentation, contact Dataverse Support at support@dataverse.org, or find help on Public Knowledge Project's support forums.